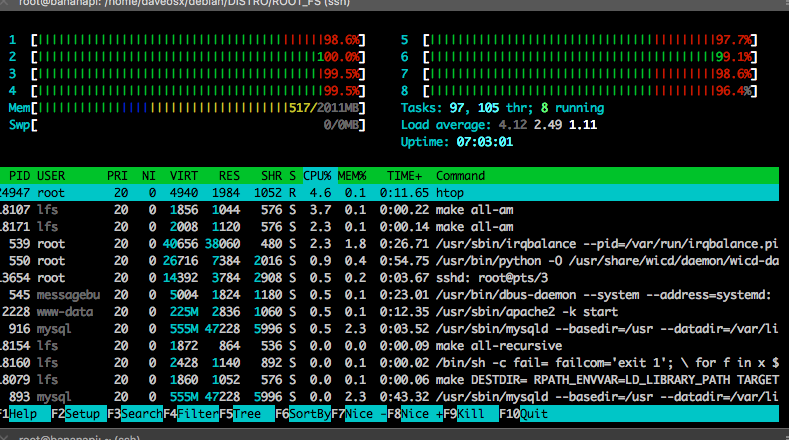
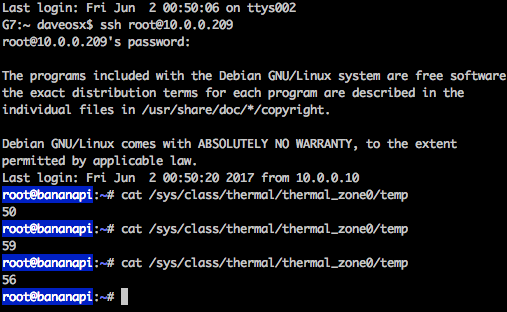
What about real loads?
sudo apt-get -f -qq -y install libcurl4-gnutls-dev
wget http://downloads.sourceforge.net/project/cpuminer/pooler-cpuminer-2.4.5.tar.gz
tar xf pooler-cpuminer-2.4.5.tar.gz && rm pooler-cpuminer-2.4.5.tar.gz
cd cpuminer-2.4.5/
./configure CFLAGS="-O3 -mfpu=neon"
sudo make
sudo make install
Cheap $0.5 heatsink from Aliexpress combined with cheap $1 5V fan connected to pin headers:
https://i.imgur.com/xZGQroh.jpg
charles@bananapim3:~/cpuburn-arm$ minerd --benchmark
[2017-06-02 11:12:34] Binding thread 1 to cpu 1
[2017-06-02 11:12:34] Binding thread 3 to cpu 3
[2017-06-02 11:12:34] Binding thread 0 to cpu 0
[2017-06-02 11:12:34] Binding thread 5 to cpu 5
[2017-06-02 11:12:34] Binding thread 2 to cpu 2
[2017-06-02 11:12:34] Binding thread 7 to cpu 7
[2017-06-02 11:12:34] Binding thread 6 to cpu 6
[2017-06-02 11:12:34] 8 miner threads started, using 'scrypt' algorithm.
[2017-06-02 11:12:34] Binding thread 4 to cpu 4
[2017-06-02 11:12:40] thread 5: 4098 hashes, 0.64 khash/s
[2017-06-02 11:12:40] thread 0: 4098 hashes, 0.64 khash/s
[2017-06-02 11:12:40] thread 4: 4098 hashes, 0.64 khash/s
[2017-06-02 11:12:41] thread 7: 4098 hashes, 0.64 khash/s
[2017-06-02 11:12:41] thread 3: 4098 hashes, 0.64 khash/s
[2017-06-02 11:12:41] thread 1: 4098 hashes, 0.63 khash/s
[2017-06-02 11:12:41] thread 6: 4098 hashes, 0.62 khash/s
[2017-06-02 11:12:41] thread 2: 4098 hashes, 0.61 khash/s
[2017-06-02 11:12:44] thread 3: 2550 hashes, 0.64 khash/s
[2017-06-02 11:12:45] thread 7: 2550 hashes, 0.64 khash/s
[2017-06-02 11:12:45] Total: 5.06 khash/s
[2017-06-02 11:12:45] thread 2: 2454 hashes, 0.64 khash/s
[2017-06-02 11:12:45] thread 6: 2475 hashes, 0.64 khash/s
[2017-06-02 11:12:45] thread 1: 2508 hashes, 0.59 khash/s
[2017-06-02 11:12:45] thread 5: 3210 hashes, 0.64 khash/s
[2017-06-02 11:12:45] thread 0: 3201 hashes, 0.64 khash/s
[2017-06-02 11:12:45] thread 4: 3201 hashes, 0.64 khash/s
[2017-06-02 11:12:45] thread 3: 642 hashes, 0.64 khash/s
[2017-06-02 11:12:49] thread 7: 3198 hashes, 0.64 khash/s
[2017-06-02 11:12:49] Total: 5.08 khash/s
[2017-06-02 11:12:50] thread 1: 2961 hashes, 0.63 khash/s
[2017-06-02 11:12:50] thread 6: 3192 hashes, 0.63 khash/s
[2017-06-02 11:12:50] thread 2: 3210 hashes, 0.63 khash/s
[2017-06-02 11:12:50] thread 5: 3222 hashes, 0.64 khash/s
[2017-06-02 11:12:50] thread 3: 3192 hashes, 0.64 khash/s
[2017-06-02 11:12:50] thread 0: 3210 hashes, 0.64 khash/s
[2017-06-02 11:12:50] thread 4: 3210 hashes, 0.64 khash/s
[2017-06-02 11:12:51] thread 7: 642 hashes, 0.63 khash/s
[2017-06-02 11:12:51] Total: 5.08 khash/s
[2017-06-02 11:12:54] thread 7: 2529 hashes, 0.64 khash/s
[2017-06-02 11:12:54] Total: 5.09 khash/s
[2017-06-02 11:12:55] thread 1: 3138 hashes, 0.63 khash/s
[2017-06-02 11:12:55] thread 6: 3159 hashes, 0.63 khash/s
[2017-06-02 11:12:55] thread 2: 3153 hashes, 0.61 khash/s
[2017-06-02 11:12:55] thread 5: 3219 hashes, 0.64 khash/s
[2017-06-02 11:12:55] thread 3: 3198 hashes, 0.64 khash/s
[2017-06-02 11:12:55] thread 7: 639 hashes, 0.64 khash/s
[2017-06-02 11:12:55] Total: 5.07 khash/s
[2017-06-02 11:12:55] thread 0: 3204 hashes, 0.64 khash/s
[2017-06-02 11:12:55] thread 4: 3204 hashes, 0.64 khash/s
[2017-06-02 11:13:00] thread 1: 3138 hashes, 0.63 khash/s
[2017-06-02 11:13:00] thread 6: 3138 hashes, 0.63 khash/s
[2017-06-02 11:13:00] thread 2: 3075 hashes, 0.63 khash/s
[2017-06-02 11:13:00] thread 5: 3219 hashes, 0.64 khash/s
[2017-06-02 11:13:00] thread 7: 3201 hashes, 0.64 khash/s
[2017-06-02 11:13:00] Total: 5.09 khash/s
[2017-06-02 11:13:00] thread 0: 3207 hashes, 0.64 khash/s
[2017-06-02 11:13:00] thread 4: 3210 hashes, 0.64 khash/s
[2017-06-02 11:13:01] thread 3: 3210 hashes, 0.64 khash/s
[2017-06-02 11:13:05] thread 3: 2556 hashes, 0.63 khash/s
[2017-06-02 11:13:05] thread 1: 3135 hashes, 0.62 khash/s
[2017-06-02 11:13:05] thread 6: 3144 hashes, 0.62 khash/s
[2017-06-02 11:13:05] thread 2: 3156 hashes, 0.62 khash/s
[2017-06-02 11:13:05] thread 5: 3216 hashes, 0.64 khash/s
[2017-06-02 11:13:05] thread 7: 3195 hashes, 0.64 khash/s
[2017-06-02 11:13:05] Total: 5.06 khash/s
[2017-06-02 11:13:06] thread 4: 3207 hashes, 0.64 khash/s
[2017-06-02 11:13:06] thread 0: 3207 hashes, 0.64 khash/s
^C
My other M3 (also 8 cores but Cortex-A53 instead of slow A7) scores almost twice as much when using friendlyarm provided fansink: http://www.friendlyarm.com/index.php?route=product/product&path=69&product_id=130
btw you know that running stock irqbalanced is a bit useless or even stupid on ARM?






{kind=link}