Hi community! My first post, after getting my BPI-F3 up and running with the Armbian image that was linked from the BPI-F3 getting started page.
Quite a lot seems to be working very nicely indeed. I installed linux-perf with apt and that seems to work fine too.
I’m posting though because I’m stuck at the hurdle of generating code that uses the vector instructions that are a key part of this beastie. The image seems to have come with a full gcc-13 toolchain, which I expected, but the compiler doesn’t appear to have anything resembling k1 or x60 in its -mcpu or -march support, and without extra command line switches the autovectorizer appears not to believe that there are vectors here: it just generates scalar fmac instructions. One stackoverflow answer I found suggested using -mrvv, but that wasn’t recognized. The gcc RISC-V options page RISC-V Options (Using the GNU Compiler Collection (GCC)) appears to suggest that -march=rv64gcv1p0zvl256b might help, and that certainly doesn’t cause the compiler to complain, but it also still fails to vectorize the most trivial of loops that both clang and gcc do a good job of on arm and amd64.
Any hints or suggestions?
FWIW the code that I’m trying to vectorize is:
void saxpy(float a, float *restrict x, float *restrict y, long count)
{
long i;
x = __builtin_assume_aligned(x, 16);
y = __builtin_assume_aligned(y, 16);
for (i = 0; i < count; i++) {
y[i] = y[i] + a * x[i];
}
}
Thanks Luca! That Compiler Explorer link was the key I needed: gcc-14 does nice rv64v vectorization, while the Armbian-default gcc-13 doesn’t. For a working set that fits in the 32k L1 cache I get a speed-up of about 4.2 with that simple saxpy loop (rather than the eight one might expect from the vector length) so I suspect that there’s still a memory or instruction bottleneck, but it’s a good start!
Also: thanks for the warning. It’s been a while since I was tracking compiler bug-fixes in real time, but the rvv v1.0 hardware is still very new.
Armbian build framework is able to compile each source with different compiler. Shouldn’t be difficult to switch. If compiler is preinstalled, I think this is all you need to do: KERNEL_USE_GCC=‘> 13.0’. I will check into if this can be defaulted.
At least few of the packages bianbu distributes are incompatible with gcc-14 (since it refuses to build faulty code), so possibly more packages will have to be updated in order to move to gcc-14.
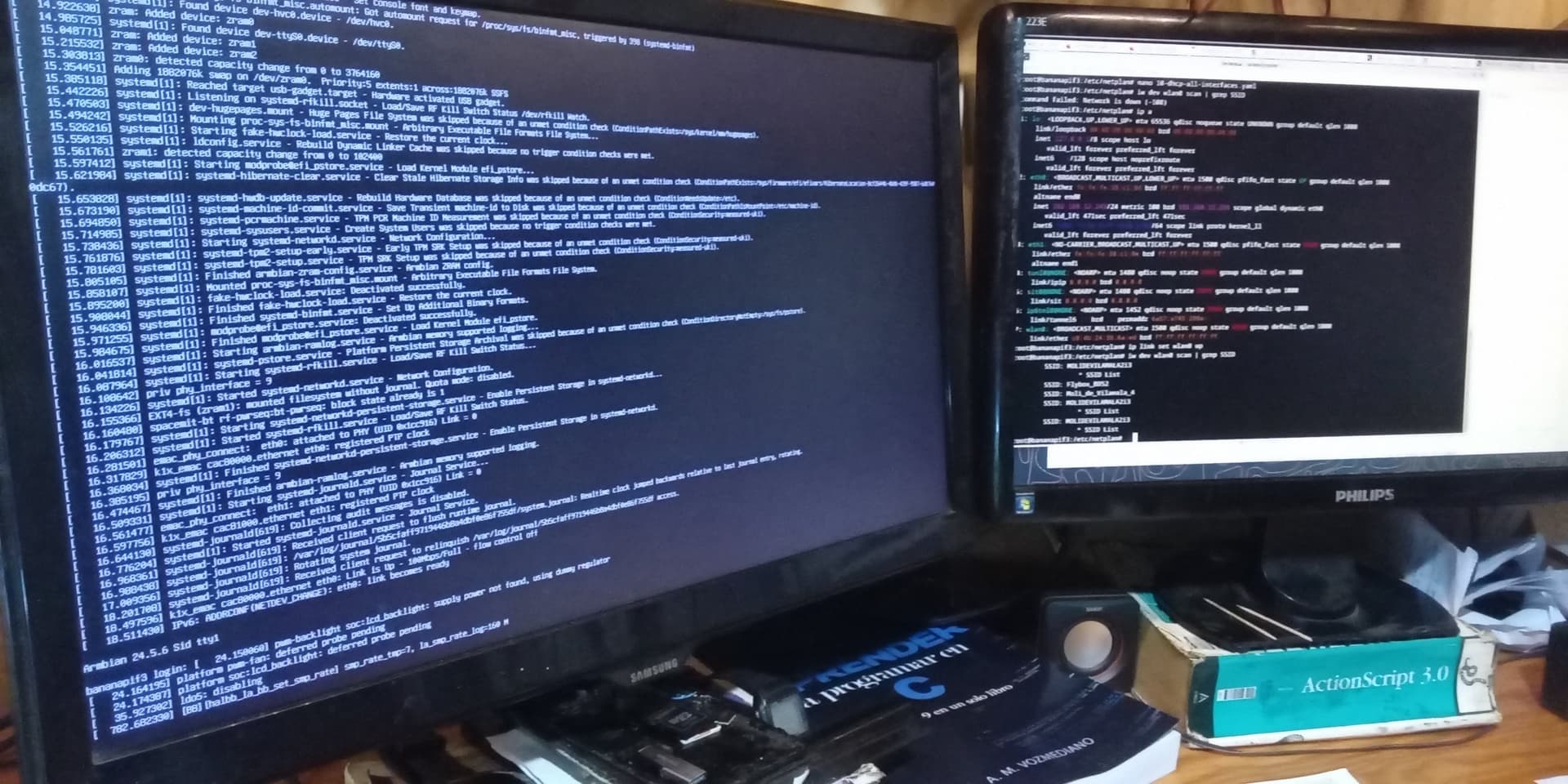
Does it have onboard Wifi support? On initial setup it ask for wireless connection but return empty SSID list.
ip address show that wlan is here:
7: wlan0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc mq state DOWN group default qlen 1000
link/ether c0:4b:24:36:6c:cd brd ff:ff:ff:ff:ff:ff
But if I install network-manager it show empty Wifi list
BTW, on installed armbian-config it doesn’t show Wifi on the network section. Looks like wifi drivers are not installed
It looks great. RISC is very interesting.
After the bananapi wiki OS, bianbu-nas and armbian-xfce.
bianbu-nas on EMMC.
I am more used to Debian configurations.
Great to see armbian-cli installed on EMMC today.
Congratulations team.
When I got the latest ISO provided on the Armbian website (the Ubuntu variant), I noticed XFCE was running very slow (it took 5 minutes even to open the system monitor). Have any of you seen this and found a solution? If I were to guess, it is due to a lack of GPU hardware acceleration.
support for SW maintenance. Currently we have two engineers on this hardware spending almost only their private time. For every 1000 USD we invest / lost, you contribute <5 USD. We are not responsible for lack of perfection.